Web scraping
at real-business scale.
I run a €500K/year data business in Madrid on scrapers I built. Same code patterns ship to clients on Upwork and direct. Native English, async, fixed-price preferred, no calls.
What I'm known for
- Self-healing AI extractors
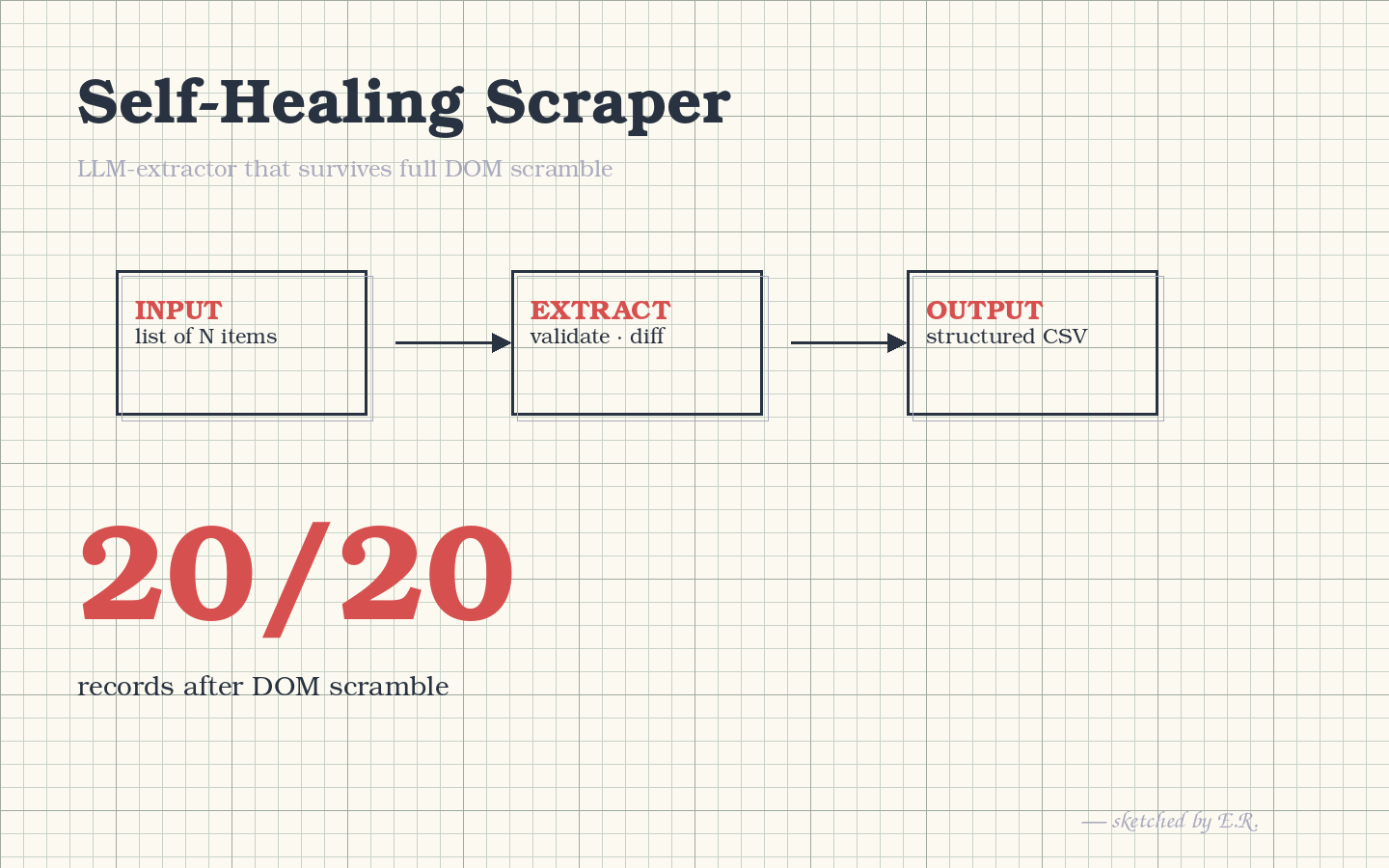
20/20 records survive a full DOM scramble. The schema is the contract; CSS selectors aren't.
- Anti-bot fluency, named
Cloudflare, DataDome, PerimeterX.
curl_cffi,nodriver, residential rotation — every tool, every tradeoff. - Pipeline-as-product
State, alerts, observability. Turns one-shot scrapes into $300-1,000/mo retainer pipelines.
- Multi-source orchestration
Parallel fan-out across HN + arXiv + HF + GitHub + PWC, normalized schema, per-source failure isolation.
Latest demos
 Demo · #01
Demo · #01
Self-Healing AI Web Extractor
A web extractor that does not break when sites redesign. Pages are converted to text and passed to an LLM with a strict JSON schema; the schema (not the markup)
 Demo · #02
Demo · #02
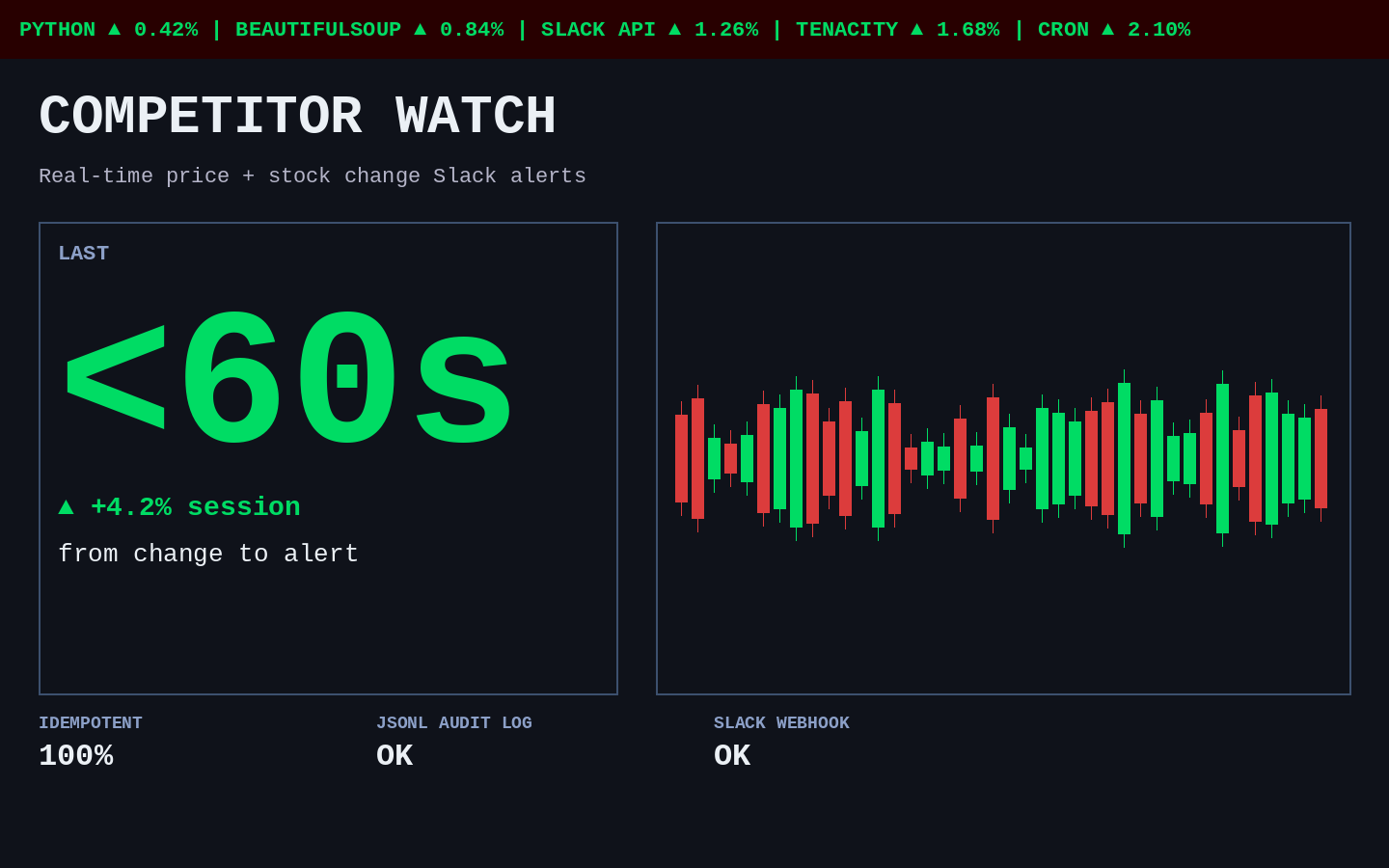
Real-Time Competitor Price Watch
Catalog-monitoring pipeline that snapshots a competitor's product list on a schedule, diffs against the last run, and posts a structured Slack alert the moment
 Demo · #03
Demo · #03
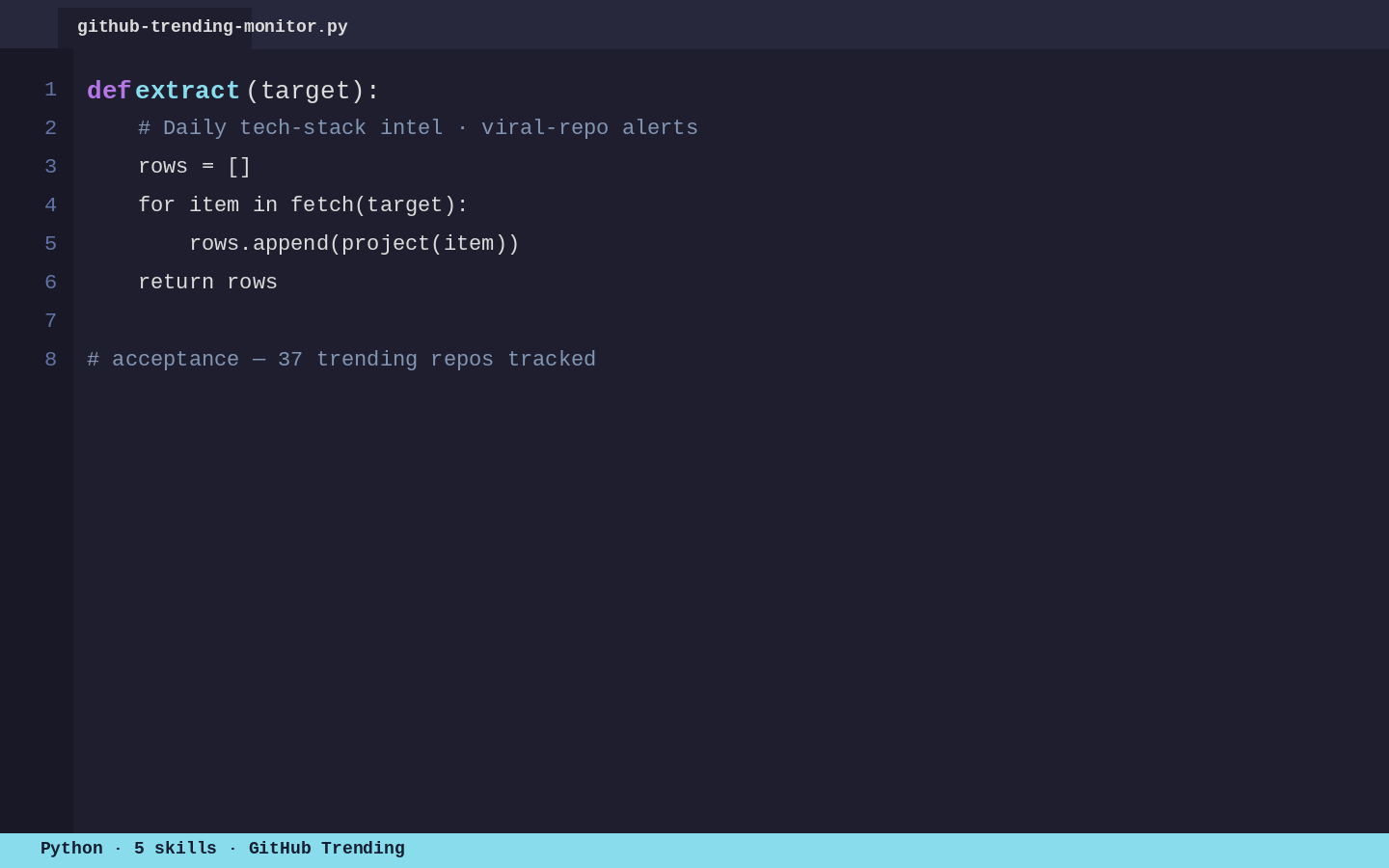
GitHub Trending Monitor
Daily monitor across GitHub's trending pages (Python / TypeScript / General). Alerts on new repos entering the trending list, star-count deltas, and language dr
 Demo · #04
Demo · #04
Government Facility Monitor
Drop-in monitor for any government / municipal / open-data wikitable listing. Extracts structured facility records (name, location, attributes), diffs against l
 Demo · #05
Demo · #05
BigCommerce Store Monitor
Production Python monitor that crawls a BigCommerce storefront's category pages on a schedule, detects inventory changes (new products, removed products, price
 Demo · #06
Demo · #06
Hacker News Monitor
Recurring monitor across Hacker News front page + newest + best feeds. Tracks every story, diffs score and comment_count between runs, fires structured alerts o
 Demo · #07
Demo · #07
Hugging Face Trending Monitor
Daily monitor across Hugging Face's trending models, datasets, and spaces via the public Hub API. Alerts on new entries, like surges, download spikes, and trend
 Demo · #08
Demo · #08
arXiv Papers Monitor
Daily monitor across arXiv submission categories (cs.AI / cs.LG / cs.CL — easily extended) via the public arXiv Atom API. Alerts on new submissions, paper revis
 Demo · #09
Demo · #09
RemoteOK Jobs Monitor
Hourly job-board monitor across RemoteOK's public JSON feed, filtered by tag (python, javascript, ai — easily extended). Alerts on new postings, salary updates,
Start here
Five plain-English guides for getting from zero to your first production scraper. Read in order.
-
7 min · Beginner
Getting Started with Web Scraping in 2026: From Zero to First Working Scraper in 30 Minutes
If you've never scraped a website before, start here. The minimum tools, the first working script, and the three things that will trip you up. Written for total beginners; no Python experience assumed.
-
3 min · Beginner
How to Scrape eBay Listings in 2026
eBay is the friendliest major e-commerce scraping target — light anti-bot, generous official API (5k requests/day free), and CSS structures that haven't drifted much in years. Here's the working stack.
-
4 min · Beginner
How to Scrape Reddit in 2026: Use the Official API (It's Cheap and the Workarounds Aren't)
Reddit closed public scraping in 2023 but kept the API affordable. PRAW + free OAuth tier handles 90% of use cases. The DIY scraping route exists but is brittle, ToS-risky, and unnecessary.
-
4 min · Beginner
How to Scrape Wikipedia (The Easy Target Everyone Overcomplicates)
Wikipedia is the simplest legitimate scraping target on the public internet. CC-BY-SA license, official APIs, no anti-bot. Here are the four ways to extract data and which to use when.
-
5 min · Beginner
How to Scrape YouTube Videos, Transcripts, and Channel Data in 2026
YouTube has three things you might want to extract: video files, transcripts, and metadata. Each has its own toolchain. yt-dlp + youtube-transcript-api + the Data API v3 cover 99% of use cases.
Hire me to build the next one
Send a target site and the data you want. I'll send a fixed-price quote and a working sample within 24 hours.
info@luba.media