Self-Healing AI Web Extractor
Self-Healing AI Extractor (Spec #1 demo)
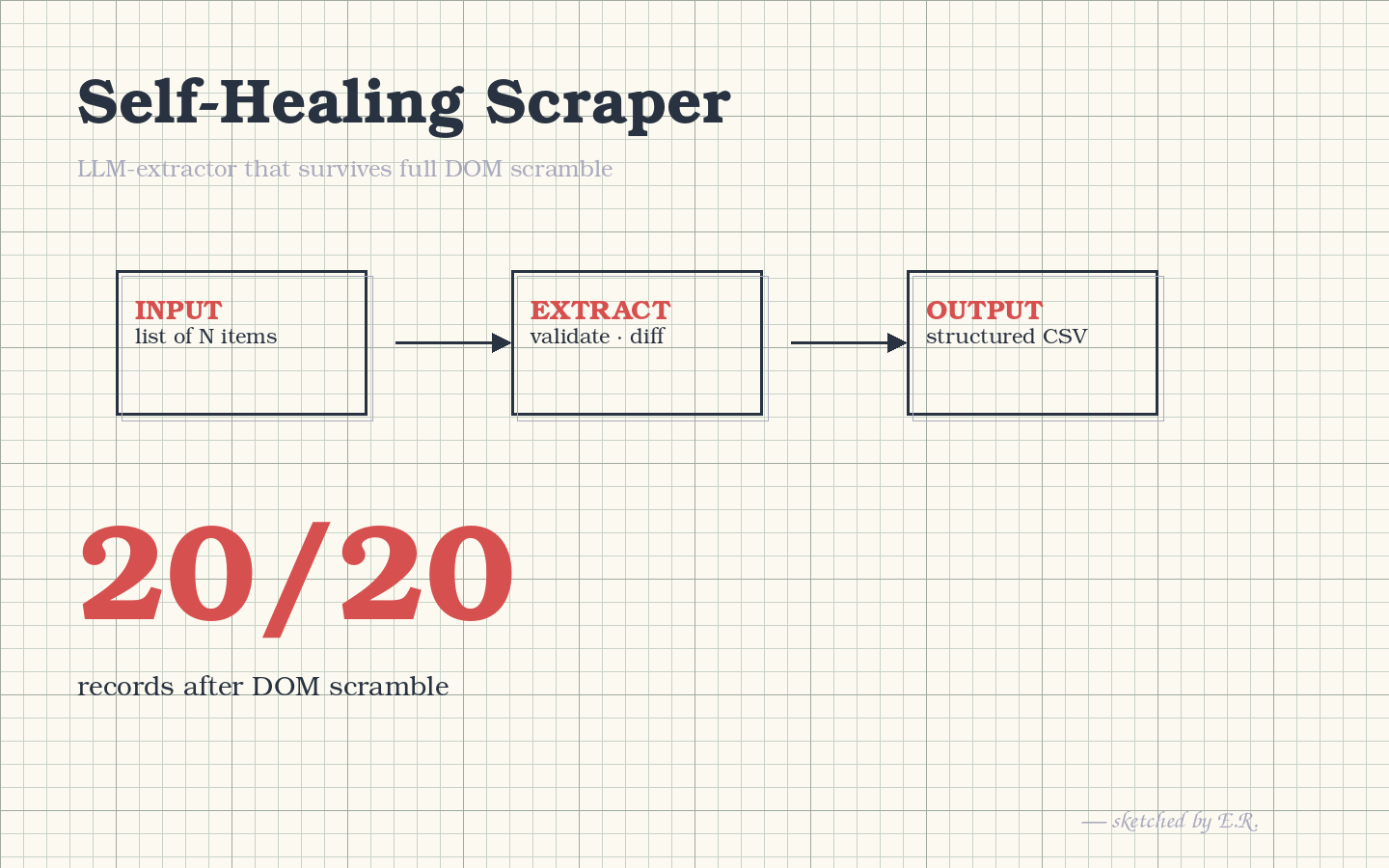
Extracts structured book data from any HTML layout — survives full DOM scrambles that would break every CSS selector.
Run
cd ~/freelance/portfolio_demos/self_healing_scraper
. ~/freelance/.venv/bin/activate
python3 test_layout_change.py # full acceptance test (passes)
python3 extractor.py http://books.toscrape.com/ # one-shot extractionResult (last run)
- Original layout: 20/20 books extracted, 20/20 prices ✅
- Mutated layout (every CSS selector broken): 20/20 books, 100% title overlap ✅
- Cost: ~1860 tokens / page (~$0.0003 with gpt-4o-mini)
What the test mutates
- All
classandidattributes stripped →,→,→- All
data-*anditempropattributes removed- Each
wrapped in extralayerA traditional CSS-selector scraper returns 0 books after these changes. The LLM-based extractor returns 20/20 — because it works at the schema layer, not the markup layer.
Files
extractor.py— the extraction logic (LLM + JSON schema)test_layout_change.py— acceptance test (mutates DOM + verifies parity)fixtures/original.html— saved snapshot for replayfixtures/mutated.html— DOM-scrambled version for the proof
Hire me to build this for your stack
Same patterns, your target site. Send the brief and I'll quote fixed-price within 24 hours.
info@luba.media- All